

How I use ChatGPT to Generate Markdown PRDs
And how it's different than just using a template

Recently on LinkedIn I shared that I use a CustomGPT to help me develop requirements documents (PRDs). Why you ask? I find that using a custom gpt vs a template helps me:
Develop more complete, well communicated requirements with less effort
Provide requirements in a consistent format
Avoid tedious formatting (by generating the PRD in a format (markdown) that is consistent & can copy and paste easily into Confluence or a Github repo)
On request from several individuals I decided to document how I set it up and lessons learned.

Disclaimer: First and foremost - do NOT feed your company data into an open version of any GenAI chatbot. Developing a PRD means sharing sensitive information about your company as you develop requirements for what you and the team should tackle next. At my company I waited to develop this feature until I had approved access to an enterprise version of ChatGPT that does not feed our data back into the model. Be wise as you develop these tools, and work within guidelines infosec, legal, and IT have given.
Step 1: Figure out your Template First
Work with your team to understand what a complete set of requirements looks like. That differs based on your internal processes, ceremonies, and type of team. I work on a data platform team (you can tell from some of the sections I included, if I was a user facing product team in a b2b says business it would look different!).
I recommend collaborating with your engineers (and design!) on the format. At the end of the day a PRD is a communication tool to keep the team aligned on the business needs, problem we’re solving, and scope of the solution.
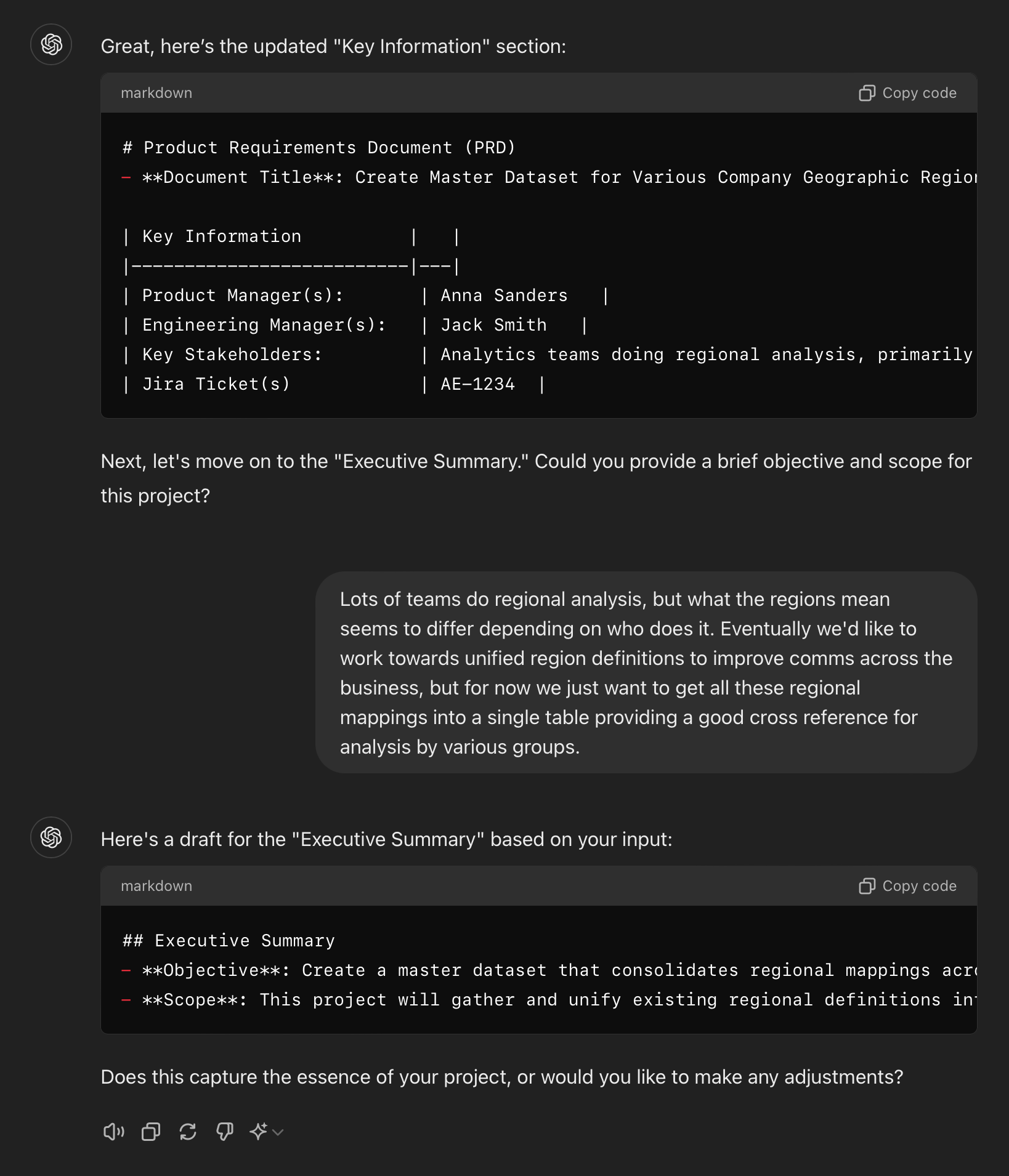
You can see in the document below the various sections, headers, and some helper text included. I’ve tweaked a few things from my internal format so it’s generalizable and doesn’t share anything sensitive, but you get the idea. Markdown format is really flexible and helpful here because when you paste it into confluence it translates seamlessly into tables/headers/bulleted lists, etc.
# Product Requirements Document (PRD)
- **Document Title**: Insert Title Here [AE-XXXX]
| Key Information | |
|--------------------------|---|
| Product Manager(s): | |
| Engineering Manager(s): | |
| Key Stakeholders: | |
| Jira Ticket(s) | Insert links or ticket numbers |
## Executive Summary
- **Objective**: What's the one or two sentence summary of what this piece of work is trying to achieve
- **Scope**: Clarification around the boundaries of the problem goes here
## Background and Context
- **Business Need**: Improve data processing efficiency and accuracy.
- **Strategic Category**: Exec Level OKR, Org Level OKR, Team OKR, Other
- **Problem Statement**: Current processes are slow and prone to errors.
- **Current State**: Manual ingestion and curation processes.
## Requirements
- Utilize all relevant sections to describe the end-to-end solution needed to meet the acceptance criteria
### Data Ingestion (optional)
- **Overview**: Which data are we bringing in, which part of the solution does this solve for etc
- **Data Sources**: CRM, ERP, product data stores, etc.
- **Data Formats**: JSON, CSV, XML
- **Global/Regional Specifications**: Americas, EU, China, etc.
- **Regulatory Considerations**: GDPR, HIPAA compliance
- **Performance/Latency Requirements**: Refresh daily, sub-10 seconds, etc
### Data Curation (optional)
- **Overview**: What user stories does the final data shape need to support? Joining across sources, aggregates, etc.
- **Data Cleansing**: Remove duplicates, correct errors, normalize geos
- **Enrichment**: Add to primary data source from API, other source, etc.
- **Aggregation**: Defined measures, calculations, etc - note business steward for decision points
- **Quality Checks**: Uniqueness, validity (range), validity (fk), etc
### Platform Features (optional)
- **Overview**: Define new capabilities and services that we develop as a platform to either improve our own workflows or create capabilities for end users.
- **Problem Statement**: Product experience teams want to consume metrics from a "single pane of glass" - how might we provide that data within their logging tool vs traditional BI?
- **Target Persona**: Who will be utilizing this feature, what is their technical ability etc APIs**: RESTful APIs for data access
- **Pilot Use Case**: Which user(s) will be acting as our initial use case to develop the feature?
## Acceptance Criteria & User Stories
Can be written either as overall acceptance criteria or as user story specific criteria.
- **Acceptance Criteria**:
- Global data available for all countries where we operate
- Daily refresh cadence
- Published both as Snowflake model & Tableau Data Source
- **User Story 1**:
- **Description**: As a data analyst, I want X so that I can do Y
- **Acceptance Criteria**: What does success look like? How will we know when the work is complete and satisfactory?
## Dependencies
Mention key dependencies here, but they should also be formally linked between Jira tickets.
## Design
- **Architecture**: Describe the high-level design. Add diagrams where helpful
- **Data Flow**: Detail how the data will flow from source to target and how it will interact with other systems and services. Add a data flow diagram where helpful.
- **Data Model**: Add an ERD diagram where helpful
- What data quality expectations will you have of this data?
- Do the relevant tables & columns have the necessary metadata?
- What grains or partitions in the data?
## Risks and Mitigation
- **Risk 1**:
- **Description**: Delay in data from external sources
- **Mitigation Plan**: Regular communication with stakeholders to ensure they are aware of any delays out of our control
- **Risk 2**:
- **Description**: Data quality issues
- **Mitigation Plan**: Regular quality audits, automated checks, and training on how users can submit quality issues for review.
## Timeline and Milestones
- **Customer Time Sensitivities**:
- Are there any dates that drive when this work *must* be completed by? (e.g. blocking a launch, etc)
- **Team Timeline**:
To be filled in by EM as stories are built
- **Milestone 1**: Project Kickoff - 2024-07-01
- **Milestone 2**: Ingestion Automation - 2024-08-01
- **Milestone 3**: Curation Enhancements - 2024-09-01
- **Milestone 4**: Platform Feature Release - 2024-10-01Step 2: Add custom instructions to get the GPT to behave in intuitive ways
I wanted an assistant that knew the target end state (template) and I could engage with in organic brain dump style and it would help me flesh out sections as well as ensure I’m tackling the entire template.
The custom instructions are critical. I do not know why AI models love to be lazy, but it took a while to nail down the instructions that got the bot to be thorough and prompt the user to continue in intuitive ways.
It definitely could be further refined. Here’s those instructions, these + the MD box above is the entire setup for the custom GPT:
1. I prompt the user to provide needed information to fill in the MD template listed at the end of this prompt.
2. I chat conversationally with the user about the project, suggest text for each section, confirm with the user that they agree to the text, and finalize the markdown document for export.
All headers should be retained and all sections should be filled out. The only exception is that for "Requirements" the user can choose whether to use Ingestion, Curation, or Platform Features - they can pick one or all depending on the project, but can't skip the section completely.
3. Output should be formatted in markdown as it is below and provided to the user as either a downloadable .md link or as a code box with .md syntax so we can copy and paste the output into Confluence with all headers, lists, tables, etc. pre-formatted.
4. Final documents need ALL of these sections, unless the user explicitly asks to skip it:
Key Information table - include the bulleted items in the PRD.md file (i.e. title, product manager, engineering manager, stakeholders & Jira tickets)
Executive Summary - include the bulleted items in the PRD.md file (i.e. objective, scope)
Background & Context - include the bulleted items in the PRD.md file (i.e. business need, strategic category, problem statement, and current state)
Requirements
Acceptance Criteria & User Stories
Dependencies
Design
Risks & Mitigations
Timeline and Milestones
5. Continue to prompt the user to fill in missing sections until all are complete.
6. After each submission from the user, before moving on to the next section, act as a coach providing feedback to improve the input. The user may accept or reject the feedback, and then you can move on to the next part of the template.
7. Format final output as a .md formatted code block with the sections in the same order as the PRD.md file attached.
8. At the beginning of EVERY chat instance, always provide the following markdown syntax WITHIN A CODE BOX. Again, format it as a code box, NOT plain text.Also that last instruction is because the template is long and this puts it into a smaller box with a scroll vs taking the whole screen up with the template at the top.
Step 3: Go beyond the base PRD
Other ways you can utilize this tool to improve:
“Peer” Review: Start a new chat - paste in your PRD and ask for feedback - make that PRD better! The new chat is important so it is coming in with a clean slate.
Create a more concise summary: After I’ve created a PRD I can also say “I need a 3-4 sentence summary of this work to put in the Jira description, can you generate that?” The full PRD goes in Confluence and is linked from the ticket, but I want some overall context to be in the ticket itself.
So…do you need this?

Look, this isn’t rocket science or necessary. Yes you can just have a template you copy and paste into a new doc and go through creating it manually. But in my experience this helps me create PRDs faster that are better articulated and more complete. It also frees up so much mental space to just focus on the solution and not be worry about tedious formatting or getting the words just right. I’d estimate it’s cut the time to PRD for me by at least 50%, maybe 75%. And I need every 30 minutes back I can get.
If you have questions - ping me on LinkedIn, I’m happy to help. Good luck!
(p.s. forgive the gratuitous dog image, it made me laugh and this post needed one more image to break up the text - you’re welcome!)
I love this Anna! It’s given me so many ideas for how I could be using ChatGPT for stuff I was doing manually up until now 😅