

The Curation Spectrum
Sandboxes, Community-Built Datasets, and Certified Data Products

Every data platform team knows the ideal state: build certified data products, shift left, get everyone working from curated datasets.
The benefits are clear—better performance, easier maintenance, reduced duplication, protection from upstream changes.
And yet, every data platform team watches analysts work around them when they can’t deliver fast enough. It creates duplicative cost, slow dashboards, and “incidents” that aren’t our fault. It feels like despite our best efforts there’s so much drift from the ideal state. I think in part this is because we are designing for a perfect ideal that doesn’t exist, without any planning for how to manage the sub-optimal chaos that happens in most organizations.
The problem isn’t that the ideal is wrong. It’s that data engineering capacity will never match business velocity, so we will always have a need for alternate paths. Questions multiply faster than headcount. Priorities shift. The analyst who needs an answer by Friday can’t wait for Q3 roadmap planning. So they find workarounds. We need a data platform that is designed to handle these curation workflows, without it becoming a chaotic, impossible to navigate, disaster waiting to happen.
Here’s what I’m proposing: three categories of data curation, each with different standards, purposes, and trust levels. I have an analogy here that I find a helpful framing — and it’s gardening related, which should not surprise you if you read this post about staying sane in data product (full of gardening analogies).

Data engineers work like industrial farmers—using powerful tools and battle-tested patterns to grow Roma tomatoes by the millions. Analysts work like backyard gardeners—planting whatever seeds they need to solve today’s problem. And in between? We need community gardens—spaces with some governance but still lots of freedom.

Let me start by breaking down why we want the ideal state in the first place, because I’ve learned that while it’s obvious to data engineers, it’s not always clear to analysts, data scientists, or business stakeholders why engineering has such a strong point of view on how curation is done. It can come across as critical of analysts—like engineers are implying they aren’t as good at writing SQL. That’s often not the intent. In reality, building at scale this way is better for the business and minimizes unintended consequences analysts might not see from their last mile perspective.
Why Data Platform Teams See Certified Data Products As Ideal
When I was an analyst I did not understand the inner workings of the data warehouse at all. We had Hadoop, then we got Snowflake — mysteriously different places data lived. I understood some analytics engineers built tables that might be useful to me, but overall I had almost no clue what data engineering was as a discipline or what best practice the data team was trying to create. I think this opaqueness of the data platform is common — we live day in and out in the operation and truly see the flow of data very differently than our stakeholders do.
We need to get better at telling the story of great data platform work, why best practices matter, and what our vision is for how data can best work at scale. Working with data engineers for several years now I have come to see why curated centrally designed and supported data products are preferred over bespoke analyst/data science built pipelines that go from raw data to model/dashboards. Now that I work with data engineers, I get why they push for certified data products. The benefits are real::
Performance: Last mile is faster and more resilient because several stages of transformation are handled for the end user.
Plus, the data gets reshaped for how you'll actually use it. Source systems are built to record individual transactions quickly—one sale, one update at a time. But analysis needs the opposite: pulling thousands of records at once to find patterns and calculate metrics. Curated products reorganize the data for analytical speed, rather than making you work with a structure designed for a different job.
All of that pre-work makes final analysis/visualization queries more efficient & fast—your dashboard query runs in seconds instead of minutes because the heavy lifting already happened upstream.Maintenance efficiency & Protect From Change: When a source system changes—say, a field gets renamed or a calculation logic shifts—the platform team patches their curated products once. That fix flows through to everyone who depends on it. Compare that to a world where 15 analysts each built their own pipeline from raw data. Now all 15 have to notice the break and patch it themselves
With a curated data product in between source and user, the data team can quickly patch their products and the fix flows through automatically to all their dependencies.Compute efficiency: In modern warehouses storage and compute are separate and compute drives a lot of the cost. The more data processed, the larger compute capacity is consumed, and the more credits it uses (credits=$$). If two people process the same data to get a common metric (retention rate, customer lifetime value, regional performance), you are literally wasting compute credits processing it twice. In contrast, when overlapping transformations happen once and users only do the final mile calc we reduce redundancy and save $$.
Discovery advantage: When curations are centralized and well-documented, people can find and trust what already exists. Without guardrails, the warehouse becomes a junk drawer—users can't tell which datasets are trustworthy, current, or even what problem they were built to solve.
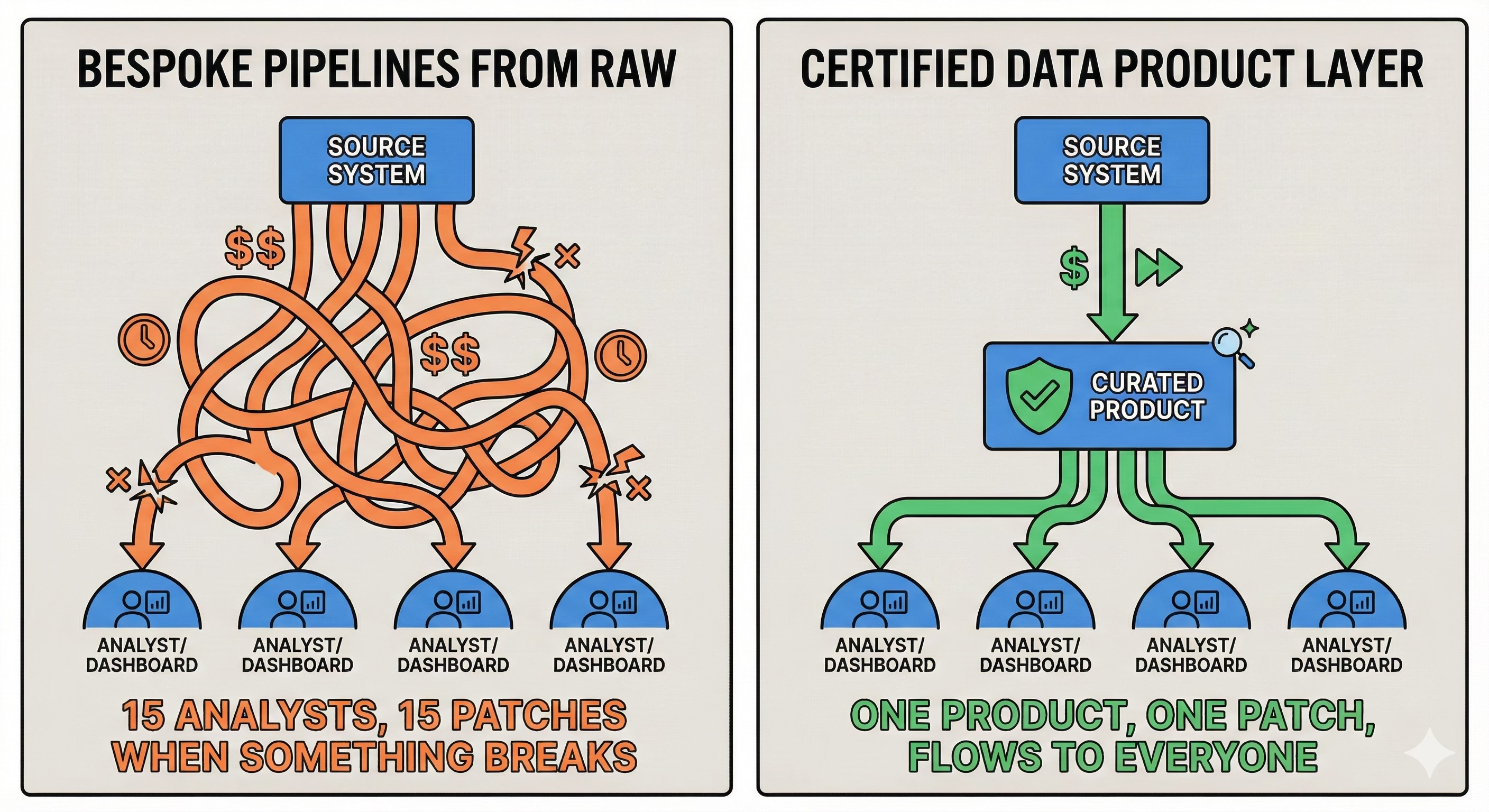
So yes, the ideal state genuinely serves everyone. The problem is — engineering can’t keep pace with analyst demand, reality intervenes and unintended consequences arise.
Reality Check: Two Ways This Goes Wrong
Building robust engineering pipelines takes time (SDLC, data modeling, product design) — a lot more time than a handful of analytical queries. Since business needs will always outpace engineering capacity—this is a structural problem, not something you fix by adding headcount.
Analysts can’t wait; the business can’t wait — as we noted in the analyst JTBD article, their role in the business is strategic partner optimizing for speed & accuracy (not scale).
When data platform teams only design for the ideal state and fail to account for this reality we get two failure modes.

Failure Mode 1: Free-for-all Warehouse
Let’s say your organization has given write permissions out freely—leadership prioritizes reducing friction over governance concerns. So analysts have write permissions across many schemas or at least in a scattered ad-hoc not intentionally designed fashion.
Pairing that freedom with the need for speed is a recipe for proliferation of bespoke curations anywhere. Your data warehouse becomes a junk drawer, real fast. Probably great stuff in there—good luck finding it. You’ll probably end up with a dried out Sharpie and no packing tape when you are headed to the post office.
This free-for-all warehouse is a nightmare for maintenance, cost, governance and discovery. The discovery problem is the most immediately costly — one of the biggest barriers to data value is finding trustworthy data with clear provenance and you’ve now worsened that situation for lesser friction in the near term.
Failure Mode 2: Shadow IT / Local Solutions
Let’s say your organization takes the opposite approach — all analysts have read only permissions. No write access at all. That prevents chaos, but guess what, the analysts still need to get the job done so they are going to find a way:
Downloading raw data to local machines for spreadsheet/IDE analysis
Building massive transformation scripts in the BI layer
Creating an under supported SQL server or shadow data lake
This creates silos that are hard to maintain amid staffing changes — knowledge walks out the door and suddenly that context was lost to their hard drive/brain and someone is trying to do forensic analysis to figure out how to reconstruct and maintain what was built.
It also creates security and IP risk when people download sensitive or very valuable data on their local machines — it’s much safer kept in the cloud.

Clearly neither of these outcomes serves the business best, but it makes sense why these patterns develop without a better plan. There’s a hybrid solution that minimizes tech debt and risk, while still giving analysts the flexibility they need when data engineering can’t move fast enough—or at all—on their problem.
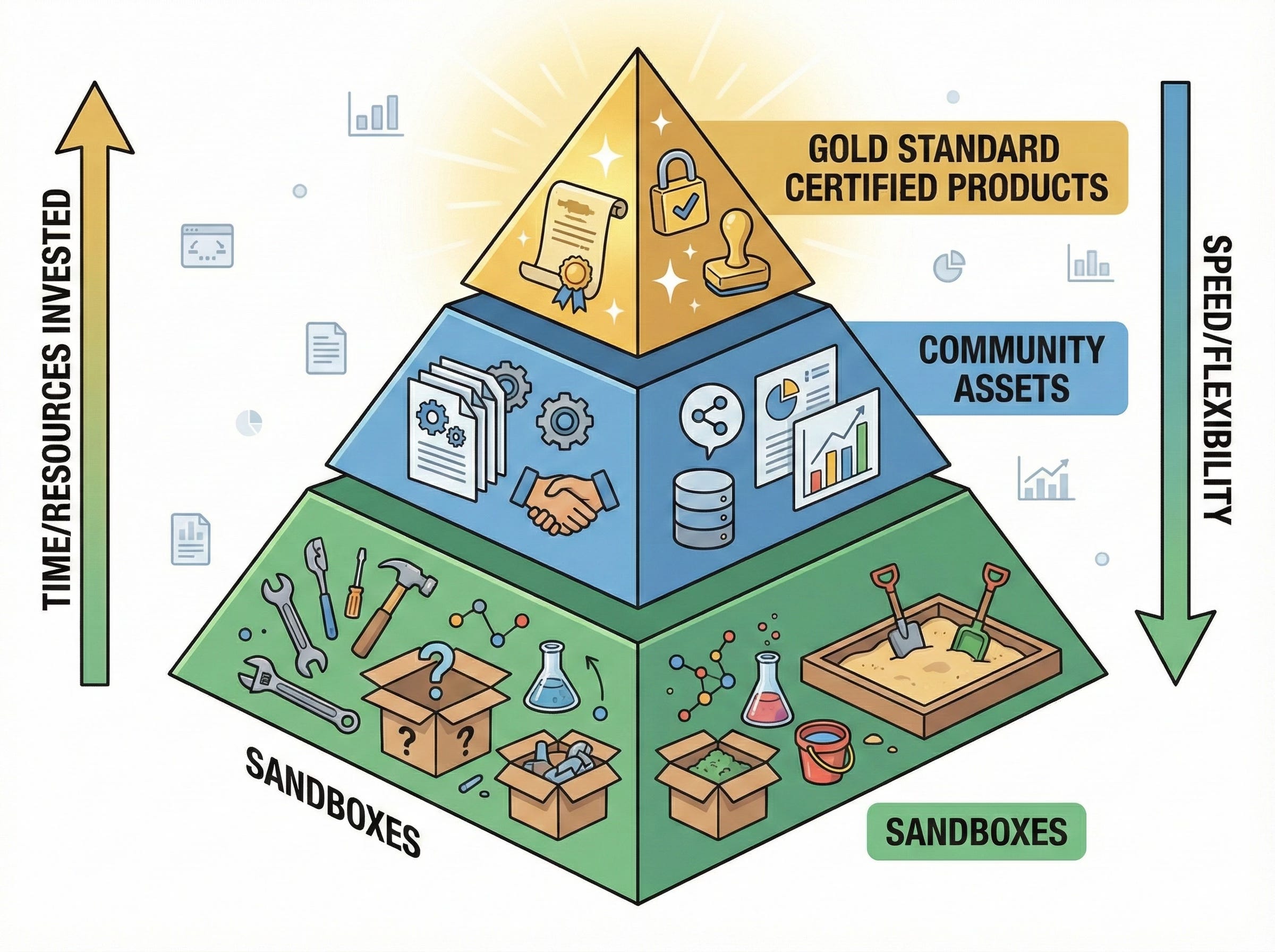
The 3 Category Curation Spectrum
What we need here is a framework that balances agility with governance, experimentation with sustainability. The goal here is to:
Enable analysts to move now (not wait for the Q3 roadmap)
Avoid single points of failure, especially for critical assets
Avoid messy warehouse with confusing provenance
Focus data engineering resources on highest-value outcomes
Design a flexible, agile process: successful experimentation → promotion → long-term centralized maintenance
Let’s return to the gardening analogy we began with to illustrate each category.
Sandboxes - The Personal Garden
Purpose: Experimentation & immediate needs
Critical Rule: No long-term dependencies on sandbox assets
There are so many tasks analysts must do which require rapid development and where the assets being ephemeral is fine. They need a scratch space - a space to quickly test things out.
The goal of enabling such a space as a platform team is to keep it contained and structure the incentives to avoid long term dependencies. Keeping the warehouse tidy means pushing all this activity to a dedicated area—physically separate from your certified products. You do not want these temporary curations appearing in the same schema alongside your certified data products - it makes the warehouse hard to browse and undermines the credibility of the other assets in that space. Make it clear when something is a sandbox and ensure that your training and company culture reiterate that it’s bad practice to put recurring dependencies against the sandbox.
Reinforce the right incentives by auto-wiping the space on a regular cadence—monthly, quarterly, whatever makes sense for your org—so analysts know this space is transient by design. If they have found valuable curations that should persist we have other spaces / ways of working to accommodate that.
Like a personal home garden—a person experiments with new things, some work brilliantly, some fail spectacularly. They enjoy the fruits of their labor and sometimes grow great stuff. But the scale and staffing behind that personal garden isn't ready to support enterprise scale.

Community Curated Data Assets - The Community Garden
Purpose: Analyst-built curations that need to persist
Critical Rule: Data platform still enforces standards like documentation, full metadata, and version control.
While experimenting—and while waiting for data engineering to fill the curation gaps—analysts create really useful assets that need to persist beyond a few weeks. So we need a low friction way to allow things to persist, but add a little more requirements to make it maintainable, transparent, and clearly defined in the catalog.
These assets shouldn't go through full SDLC like certified products, but they do need some standards:
Version controlled - Centrally stored code with change tracking—we need to know when things changed and what changed
Governance - Clear ownership: who maintains this? Where do incident tickets go?
Access controlled - Managed access permissions — if we have role based access controls, we need to ensure that analysts can’t break the RBAC model by freely sharing.
Documented - Minimum metadata standards: table/column descriptions, stewardship info, known issues, etc.
Clearly flagged as community led & no-SLA: Clearly flagged as community-led & no-SLA: Anyone who discovers these assets needs to know they're not held to the same standards as certified data products. Think Chrome extensions—not guaranteed by Google, not as robust as Chrome itself, but they must meet baseline standards to be in the store. Lots of gems, some duds, and a few that seemed perfect until you got into the details.
By creating just enough friction you create a small barrier to entry so that someone must want the asset to persist bad enough to go through it. But not so much friction that it feels like an undue burden. Documentation, version control (programmatic or via ticket if analysts aren't git-savvy), and incident ownership—none of these are giant barriers. But they do signal that persistence requires a bit more care.
And for the central data engineering team this is a small but maintainable task once the workflow is designed. They aren’t expected to do a substantive code-review on what the query does, just ensure it runs, commit it to git, and schedule it to refresh on the expected cadence. We’re allowing things to persist without allowing too much chaotic curation and without investing in a bunch of engineer overhead.
Like a community garden—just enough rules to let everyone coexist peacefully. People might garden alone or share their harvest, but there's no expectation of industrial-scale production.

Gold Standard Certified Data Products - Industrial Farming
Purpose: Scalable, well modeled data assets supported by engineering best practice, to support the organization's most critical analytics, AI/ML products, and operational data flows..
I’ll be brief here, because I’ve written extensively about data products and will again. (Exhibit A, below)
Data Products as Modular Components - A Flexible Framework

A few weeks ago on LinkedIn I posted about how I think about data products as a container for a set of modularized components. In that post I shared this diagram 👇🏻
What makes data products different:
Data product managers conduct discovery - understanding actual user needs, not just requests, and building reusable components that scale across use cases
Intentional data modeling (designed for performance, maintainability, interoperability)
Full SDLC: testing, code review, deployment processes
Clearly articulated SLAs, observability and structured incident response
Comprehensive documentation (not just table descriptions—context, usage patterns, lineage, dependencies)
Change management controls (backward compatibility, deprecation processes)
This tier exists to deliver our highest level of trust, support, and reliability. The business can rely on these data products for mission-critical decisions and workflows. They should be clearly marked in the catalog as distinct certified data products. And they should evolve over time as new use cases arise and we iterate on their design—just like any product.
The big tradeoff: time and engineering resources, which are always scarce. So we are careful about which use cases we select for this level of investment. That’s why the other two tiers are necessary — to free us up to focus deeply, not be spread too thin, and still meet the needs of the organization.
I like the analogy of industrial farming here because that type of agriculture focuses on limited crops, high reliability, mitigating risk, and addressing issues quickly. On farms many people work as a team to deliver at that scale — it’s not about bespoke delivery, but clearly planned and well maintained consistency. And it feeds millions predictably, even amid sometimes volatile conditions.

So we have three tiers—each serving different needs, each with different tradeoffs. Sandboxes for speed and experimentation. Community assets for persistence without full engineering overhead. Certified products for scale and mission-critical reliability. But I can hear the objection already: doesn't this just create technical debt everywhere? Let's address that head-on.
Strategic Compromise: How We Prevent Tech Debt from Overwhelming the System
I can already see the skeptical faces of the data engineers - you’re worried about the potential for tech debt. But the key point I want to emphasize is that this framework is about balancing the need for speed while mitigating as many of the downsides as possible. We are not letting debt accumulate unchecked — we’re designing systems that naturally clean up or promote. And if we do nothing the organization accumulates tech debt somewhere — it’s just local to machines or in the BI layer or some other chaotic solution we’ll learn about down the line.
To reiterate, here are the three mechanisms that prevent debt from spiraling out of control.
Sandbox Auto-Expire
Sandbox auto-wiping at a regular interval (monthly or quarterly) prevents persistence and dependencies
No tech debt can accumulate in tier 1, it’s structurally impossible
The system enforces ephemerality
Semi-automated Cleanup in Community Maintained Layer
Observability on the community led assets tracks usage
Unused assets trigger notification to the analyst maintainer
Auto-removal on X date unless we hear from them
Light touch, but effective
Promotion Pathways
The same usage observability from the last mechanism also helps us find diamonds in the rough that we may want to promote to fully supported data products
Those trigger product to do discovery - what are people using this for? what’s missing from the certified data product layer and how can meet this same need in a more stable way backed by testing, SLAs, etc.
We normalize to best practice development standards and reduce duplication
The community garden becomes one place great ideas bubble up for further investment
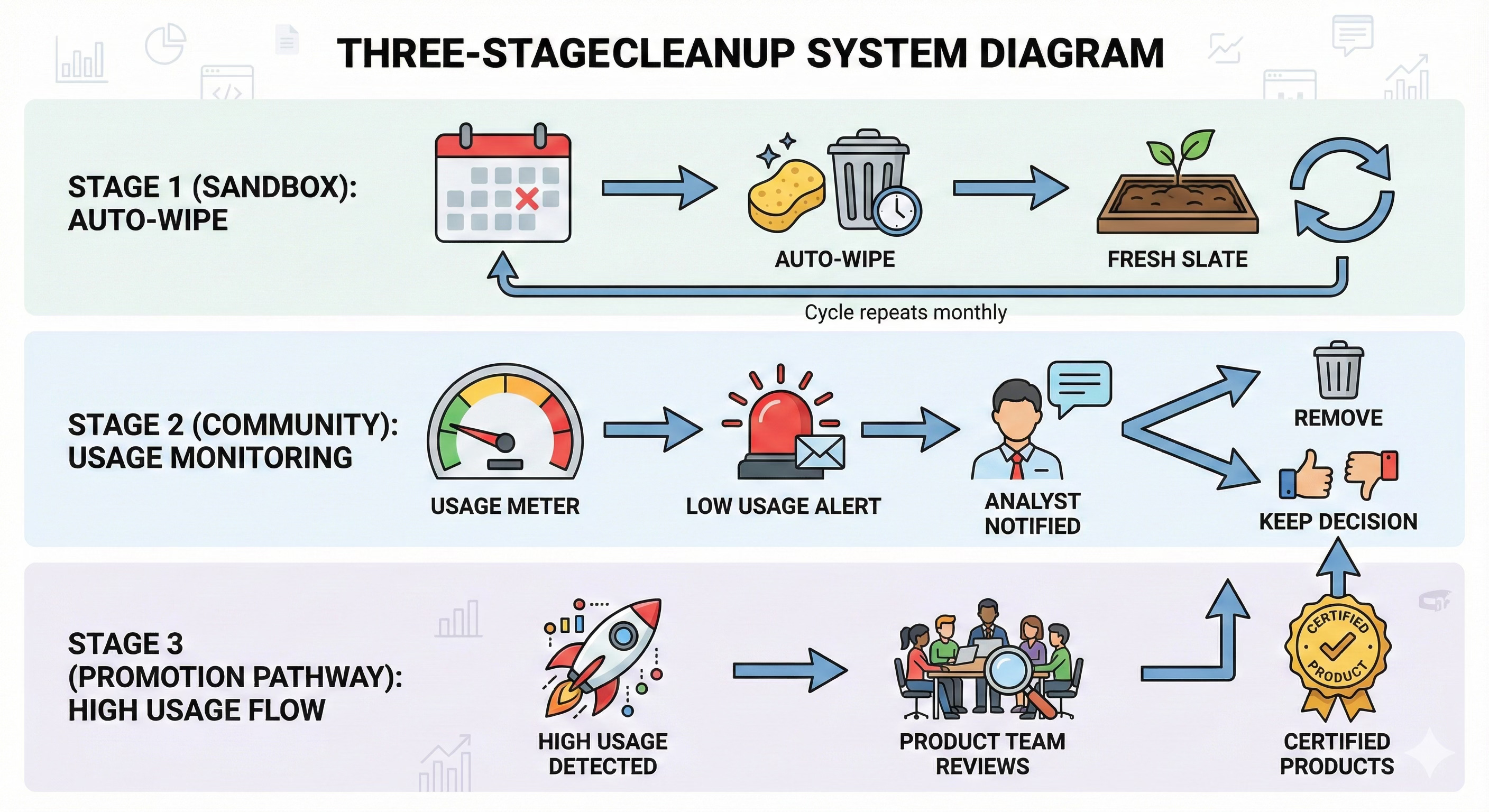
This really isn’t about lowering our standards. It’s about allowing small amounts of tech debt to meet business needs today. And it’s about using automation to help us prune and promote. It’s a strategic compromise with guardrails. Designing for the reality we have instead of holding out for all ideal state — which is just never achievable in practice.
We Need All Three: Planning for Reality Over Fighting It
The ideal state—everyone building on certified data products—is appealing on its face, but in reality — the business just needs more flexibility.
Let’s design for reality instead. We need all three tiers to feed the organization: personal gardens for the analyst who needs answers this week, not next quarter. Community gardens where people share their work and discover what’s useful. Industrial farms that reliably deliver at scale, year after year.
They work together as a system. Successful sandbox experiments inform what should persist in community assets. High-usage community assets surface what deserves promotion to certified products. The observability becomes your roadmap—you’re not guessing what to build, you’re watching what the organization actually uses alongside your other methods of discovery and engagement.
This isn’t lowering standards. It’s designing standards that work with reality. The auto-wipe prevents sandbox sprawl. Usage monitoring keeps community assets from accumulating. Promotion pathways ensure good work graduates to proper support. It’s strategic compromise with guardrails.
When we only plan for the ideal, without alternatives: it doesn’t eliminate the sub-optimal workstreams, it pushes it into shadows—local downloads, BI layer transformations, databases that become single points of failure. We’ve all seen this before.
So have this conversation with your team. Help them understand that meeting the business needs requires a multi-pronged approach. Brainstorm together. What would intentional sandboxes look like? What standards make community assets work? What truly deserves certified product treatment?
The goal isn’t perfection. It’s a data platform that serves the business as it actually operates. And that tends to always be a little faster, a little more chaotic, and a little more unplanned than we’d like — so let's plan for it.
Amazing article, Anna. Really echoes what we stumble upon out there in the real world.
I really liked how you suggested a path to detect and promote highly used community assets into full-fledged data products. It gives us a way to keep technical debt under control. However, I still expect some friction in convincing the analysts to give up ownership of these assets to the data management team.
Excellent article, Anna. This really resonates a lot with our current focus on trying to formalize and increase onboarding spead into the Data Platform... And then how we can acelerate and automate in best ways the journey from Sandbox to Community Garden. Your Gardens / curation spectrum provides a great mental model , thanks